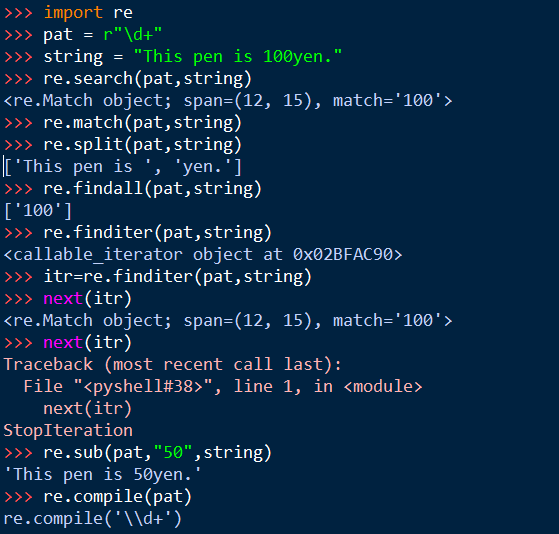
import re
words=["orange","october","octpus","order","banana","baby","busy"]
# 正規表現のパターンに一致するものを画面に出力
pattern = r"oc.*"
print("ocで始まるパターン=",pattern)
for word in words:
if re.match(pattern,word):
print("-",word)
pattern = r"b.*y"
print("bで始まりyで終わるパターン=",pattern)
for word in words:
if re.match(pattern,word):
print("-",word)
matchオブジェクトについて
プロパティ
意味
match.expand(template)
sub()メソッドと同様にマッチした文字列でtemplate文字列を置換
match.group([g])
マッチしたサブグループgを返す
match.groups()
パターンにマッチしたサブグループの一覧を返す
match.groupdict()
名前付きのサブグループを辞書型で返す
match.start([g])
グループgとマッチした部分文字列の先頭のインデックスを返す
match.end([g])
グループgと マッチした部分文字列の末尾のインデックスを返す
match.span([g])
グループgに関して、(start,end)のタプルを返す
import re # 正規表現reモジュールを取り込む
# 先頭と末尾の指定があるので「abc」の文字列だけにマッチ
re.search(r"^abc$","abc")
# abcdやxabcはマッチしない
print(re.search(r"^abc$","abcd"))
print(re.search(r"^abc$","xabc"))
# 任意のファイル拡張子を調べる
pat = r"\.png$"
re.search(pat,"abc.png")
# 末尾が.pngでなければマッチしない
print(re.search(pat,"abc.png-doc.txt"))
words = ["soy","soup","nuts","spot"]
pat = r"^s...$" # sから始まる4文字の文字列
[i for i in words if re.search(pat,i)]
# 繰り返し
re.search(r"ba*","b")
print(re.search(r"ba+","b"))
re.search(r"ba?","b")
re.search(r"ba*","baaaaaaa")
re.search(r"ba+","baaaaaaa")
re.search(r"ba?","baaaaaaa")
re.search(r"ba{3}","baaaaaaa")
re.search(r"ba{1,3}","baaaaaaa")
re.search(r"ba{3,}","baaaaaaa")
import re
# 最小単位の繰り返し
s= "赤巻紙青巻紙黄巻紙"
re.findall(r".+紙",s)
re.findall(r".+?紙",s)
# 文字集合の指定[...]
zipre = re.compile(r"^[0-9]{3}\-[0-9]{4}$") # 正規表現パターンをコンパイル
zipre.search("440-0012")
print(zipre.search("4401-0012"))
# 単語の選択"|"
s = "I like red colour."
pat = r"\w+ (color|colour)"
re.search(pat,s)
# グループ(...)
s = "date:2019/10/15"
pat = r"(\d{4})/(\d{1,2})/(\d{1,2})"
g=re.search(pat,s)