Python(機械学習でワインの美味しさを判定)
- UCI機械学習リポジトリ
- 機械学習では、どのようにしてデータを収集するのかが大きな課題。
機械学習に使えるデータを収集し公開している「UCI機械学習リポジトリ」からワインに関するデータをダウンロード
- 機械学習では、どのようにしてデータを収集するのかが大きな課題。
UCI機械学習リポジトリ > Wine Quality Data Set
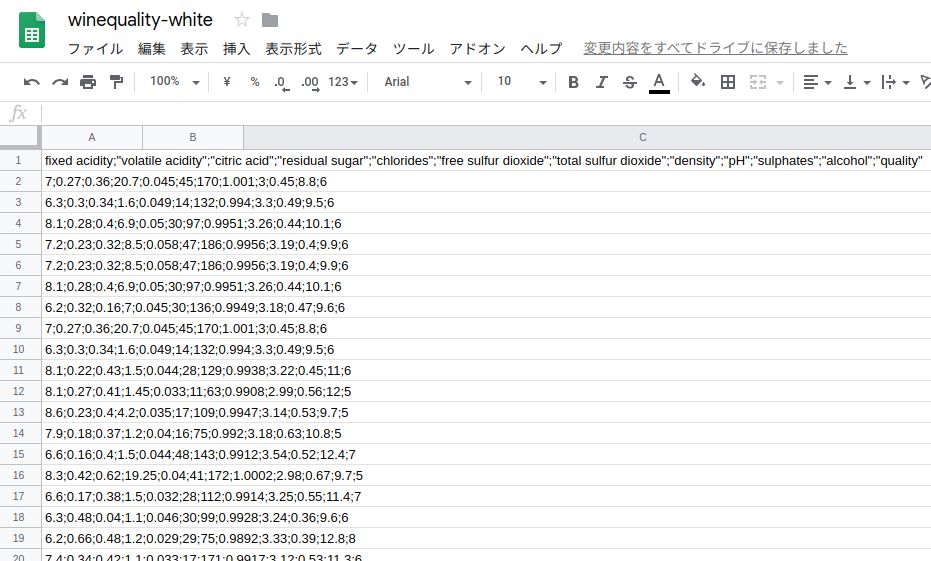
[winequality-white.csv]
- csvファイルのフィールド一覧
- 1列目から11列目がワインの成分
12列目が専門家の評価 (0まずい〜10美味しい)
機械学習ライブラリ「scikit-learn」で学習器にデータを学習させる場合
- データの配列とラベルの配列を分けておく必要がある
- データ(1列目から11列目がワインの成分)
ラベル(12列目が専門家の評価)
from sklearn import svm,metrics
from sklearn.model_selection import train_test_split
# ワインデータ(CSV)を読み込む
wine_csv = []
with open("/home/g6no3/winequality-white.csv","r",encoding="utf-8") as fp:
no = 0
for line in fp:
line = line.strip()
cols = line.split(";")
wine_csv.append(cols)
# 1行目はヘッダ行なので削除
wine_csv = wine_csv[1:]
# CSVの各データを数値に変換
labels = []
data = []
for cols in wine_csv:
cols = list(map(lambda n: float(n), cols))
# ワインのグレードを調整
grade = int(cols[11]) # 末尾のデータがワインのグレード
# 少なすぎるサンプルを調整
if grade == 9:
grade = 8
if grade < 4:
grade = 5
labels.append(grade)
data.append(cols[0:11]) # ワインの成分データ
# 訓練データとテスト用データに分ける
data_train,data_test,label_train,label_test = \
train_test_split(data,labels)
# SVMのアルゴリズムを利用して学習
clf = svm.SVC()
clf.fit(data_train,label_train)
# 予測してみる
predict = clf.predict(data_test)
# 結果を表示する
as_score = metrics.accuracy_score(label_test,predict)
cl_report = metrics.classification_report(label_test,predict)
print("正解率=",as_score)
print("レポート=\n",cl_report)- csvファイルの読み込み
- csvファイルを扱うモジュールがあるが、今回はファイルを読み込み、自力で解析する。
- open()でファイルを開き、for構文で1行ずつデータを読み込む。
(csvファイルは1行が1レコードとなっているため) - str.strip([文字集合])
- 先頭と末尾にある文字集合を削除したものを返す。文字集合を省略すると空白文字を削除。
- str.split(区切り文字[,回数])
- 文字列を区切り文字で分割する。
- 文字列のスライス
- wine_csv[1:],cols[0:11]
- その他記述
先頭略n[:5], 後ろから指定n[-3:], stepずつn[0:9:2] - floatに変換
- csvを二次元リストに変換しただけでは、各値はstr型なので、float()で数値に変換する。
- map(function,iterable)関数
- 第一引数の関数を、第二引数のリストの要素全てに対して適用し、結果を返す。
- ワインのグレード調整
- 実際のデータには、3〜9のグレードしか無く、グレード3,4,9の値は非常に少ないデータしか存在しない。
そのまま学習させると、データが少なすぎるエラーが出るので修正。
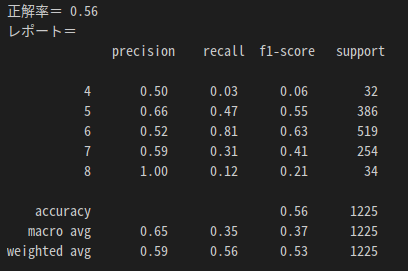
[実行結果(SVM)]
チューニング
- 正解率の精度が55%程で、良い正解率ではないのでチューニングが必要
- ランダムフォレストのアルゴリズム
- SVMのアルゴリズムで分類したが、精度の高いことで有名なランダムフォレストのアルゴリズムに変更
- scikit-learnでは、アルゴリズムを変更しても、データの訓練はfit()メソッド、データの予測はpredict()メソッドと、APIが統一されている。
# ランダムフォレストのアルゴリズムを利用して学習
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(data_train,label_train)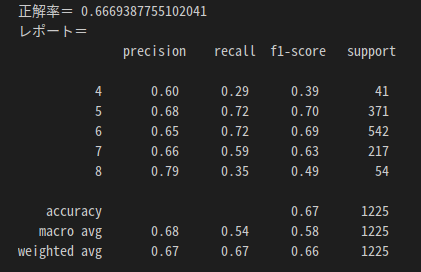
[実行結果(ランダムフォレスト)]
- 正解率の精度が67%程に改善
- さらに評価5,6、7,8の差はほぼないとし、正解の判定を甘くして再評価
# 予測してみる
predict = clf.predict(data_test)
total = ok = 0
for idx,pre in enumerate(predict):
# pre = predict[idx] # 予測したラベル
answer = label_test[idx] # 正解ラベル
total += 1
# ほぼ正解なら、正解とみなす
if(pre-1) <= answer <= (pre+1):
ok += 1
print("正解率=",ok,"/",total,"=",ok/total)
[実行結果(甘い評価)]
- 正確な分類ではないが、正解率96%からワインの美味しさ(グレード)は、その成分から分かることが言える。
ワインの成分を視覚化
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
# ワインデータ(CSV)を読み込む
wine = pd.read_csv("/home/g6no3/winequality-white.csv",delimiter=";")
# ワインのグレードを表す列だけ取り出す
y = wine["quality"] # label
# 3Dで描画
xname = "alcohol"
yname = "sulphates"
zname = "total sulfur dioxide"
plt.style.use('ggplot')
fig = plt.figure()
ax = Axes3D(fig)
ax.set_xlabel(xname)
ax.set_ylabel(yname)
ax.set_zlabel(zname)
ax.scatter3D(
wine[xname],
wine[yname],
wine[zname],
c=y,s=y**2,cmap="cool")
plt.show()- Pandasライブラリ pd.read_csv()
- 数表データの操作を行うライブラリで、CSVファイルの読み込み
- wine["quality"]
- PandasではCSVの1行目にヘッダ行があれば、その名前を使って、フィールドを取り出すことができる。
- matplotlibライブラリ
- データを視覚化することができるライブラリ。
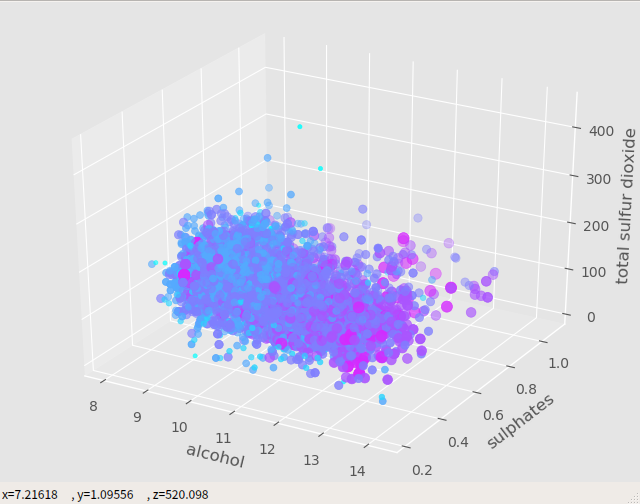
[3要素を取り出して3D描画]
